·Mergestorm Team·Engineering
3 Strategies to Fix AI Death Spirals in Agentic Review Loops
What an AI death spiral looks like in review + auto-patch pipelines, and three engineering levers — severity gates, shared memory, and consistency guards — that stop agents from fighting over the same PR.
Agentic review plus auto-patch is one of the highest-leverage workflows in modern engineering: an AI reviewer flags issues on every push, and a patch agent commits fixes straight to the branch. Done well, it feels like a tireless senior engineer paired with a fast junior who never sleeps.
Done poorly, it becomes an AI death spiral — the PR stays open for hours, bot commits stack up, humans stop reading the thread, and the diff grows while the original problem never really gets resolved.
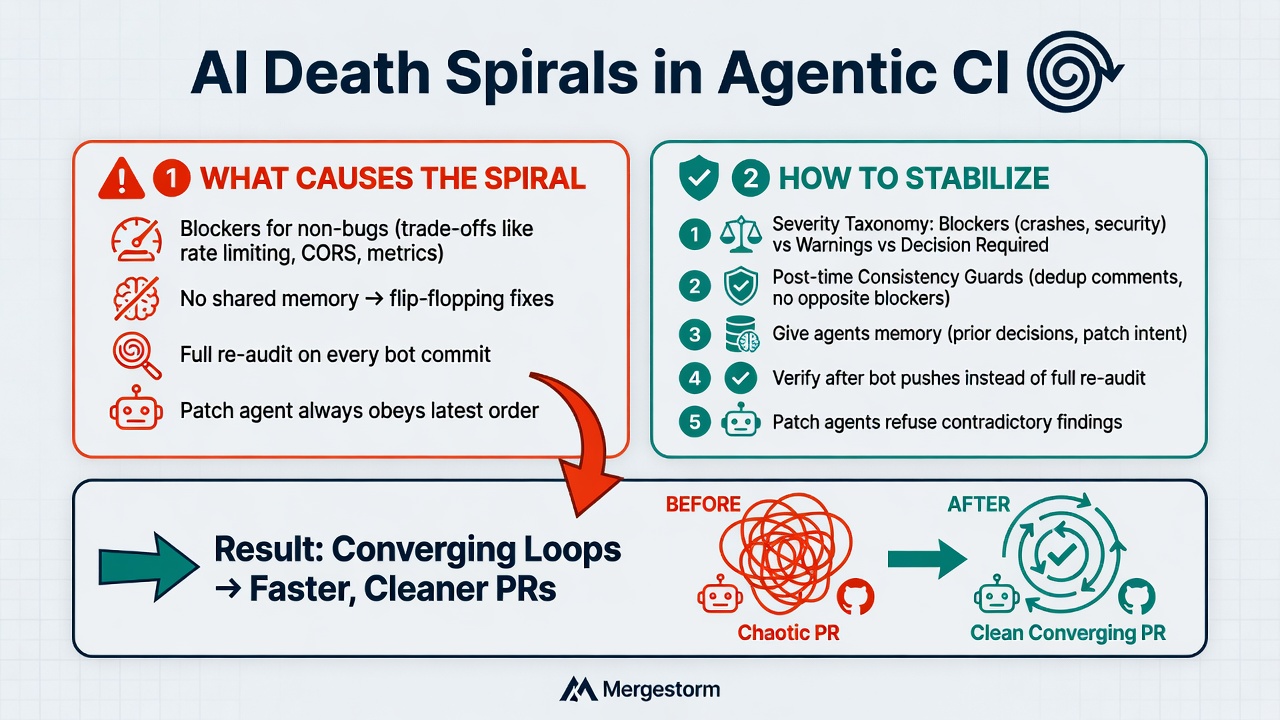
We run this loop in production (Vortex reviews, Cyclone patches) and have hit the spiral more than once. This post explains what the death spiral is in agentic loops, then three strategies that actually stop it — without ripping out automation.

Watch: the loop, the spiral, and three fixes
This walkthrough covers the agentic review pipeline, what a death spiral looks like when Vortex and Cyclone flip-flop with no guardrails, and the three stabilization strategies below.
What is an AI death spiral?
An agentic review loop is a feedback cycle on a pull request:
- Review agent (Vortex) posts findings on the diff.
- Patch agent (Cyclone) commits fixes for blockers.
- Review runs again on the new head.
- Repeat until the PR is merge-ready.
That loop is supposed to converge. A death spiral is when it oscillates instead — same files, opposite prescriptions, dozens of bot commits, hundreds of comments, and humans tuning out.
The pattern is always the same:
- Review posts a blocker on a changed line.
- Patch commits a fix.
- Review runs again and posts another blocker — often on the same file, sometimes the opposite of last pass.
- Patch obeys and undoes the previous fix.
- Repeat until someone merges manually, disables auto-patch, or goes home.
From the outside it looks like the agents are "being dumb." From the inside it is usually a feedback loop design problem: two agents with conflicting incentives, no shared memory of decisions, and no distinction between "this is objectively broken" and "this depends on how you deploy."
We have seen pull requests accumulate 50+ auto-patch commits while code on contentious lines oscillates between two equally valid answers. That is not a model-quality issue alone. It is what happens when every pass treats trade-offs as emergencies.
Why the loop keeps spinning
Blockers for things that are not bugs. Rate-limit identity behind a proxy, CORS strategy, metrics semantics — two senior engineers could disagree in a design review. When the review agent posts these as hard blockers, Fix A satisfies pass N, pass N+1 demands Fix B, pass N+2 demands Fix A again.
Prompt-only consistency does not survive pressure. "Do not flip-flop between opposite fixes" in the system prompt helps intent. It does not enforce behavior when a reworded blocker looks new.
The patch agent always obeys the latest order. Blocker means fix now — correct for real defects, catastrophic for contradictory blockers.
Every push triggers a full re-audit. Verification asks: "Did the finding I raised get fixed?" Re-audit asks: "What else can I find?" Re-audit on a hot loop is how you get nine versions of the same comment with different names.
Three strategies that stop the spiral
You do not need to cap retries at three and call it a day. The teams that get the most from agentic review treat it like distributed systems: explicit contracts, memory, and gates.
These three levers remove most of the fuel we have seen in production spirals.
Strategy 1: Severity gate — trade-offs are decisions, not blockers
Reserve blocker / request-changes for issues with one demonstrably correct fix: crashes, auth bypasses, data loss, broken tests.
Everything else gets a lower tier:
- Warning for real but non-blocking issues.
- Decision required for deployment-dependent trade-offs — post once, list both options and the assumption each depends on, never alternate prescriptions across passes.
If both answers are valid under different assumptions, it is not a blocker. Cyclone should not auto-patch a trade-off war.
This single change removes the fuel for half the spirals we have seen.
Strategy 2: Shared memory — past comments feed back into review
Prior comment history in the review prompt helps. Structured memory helps more:
- What did the patch agent change last commit, and why?
- Which finding was it addressing?
- Was this a deliberate trade-off?
Commit subjects alone ("fix: adjust proxy trust") do not tell the next pass that the choice was intentional. A rolling PR decision log — or feeding resolved outcomes back into Vortex — lets the review agent verify instead of re-open.
Strategy 3: Consistency guard — no duplicate blockers on the same spot
Before a review comment goes to GitHub, check it against prior bot feedback on the same PR:
- Same file, same neighborhood, already flagged as a blocker? Do not post another blocker there — the thread exists.
- Code now matches what you recommended last time? Skip or mark resolved.
- New recommendation is the semantic opposite of a prior one? Escalate as a single decision comment; do not start a new blocker war.
This is not a circuit breaker that gives up after N tries. It is making the reviewer consistent — the behavior your prompt already asks for, backed by code.
Supporting practices (still worth doing)
These complement the three strategies above:
- Verify after bot pushes. Ask "did we fix the specific finding?" not "what else is wrong on every touched line?"
- Let patch agents refuse contradictory batches. When two open findings prescribe opposite changes, surface one human-visible note instead of picking a side.
What we shipped in Mergestorm
Two focused levers map directly to strategies 1 and 3:
Review prompt (severity gate): deployment-dependent trade-offs — rate-limit identity behind proxies, CORS strategy, trust settings — are explicitly not blockers. They must be raised once as a decision-style warning with both options spelled out.
Post-time guard (consistency): before posting, suppress a new blocker on a spot where our review bot already left an inline comment on that file in the same PR. Warnings and informational notes still flow through — they do not force another patch cycle the way blockers do.
Shared memory for patch outcomes is an active area — structured context in the review prompt is already in place and we are extending it.
Early result: fewer re-triggered patch runs on the same hunk, less noise in the PR timeline, humans spend time on real defects instead of watching bots argue with themselves.
Checklist if you are building your own loop
- Blockers are scarce. If two senior engineers could disagree, it is not a blocker for your bot.
- Decisions are posted once. Trade-offs get a warning with assumptions, not alternating errors.
- Review remembers the PR. Prior bot comments inform the next pass; gate duplicate blockers in code.
- Patch verifies, review re-audits selectively. Bot commits should trigger "did we fix it?" not "what else is wrong?"
- Contradictory findings stop the patch agent. Never auto-pick between two reviewer blockers on the same concern.
The payoff when it works
When the loop converges, agentic review + patch feels like compound interest:
- Trivial defects never reach a human reviewer.
- Fixable issues land on the branch before standup.
- Humans review architecture and product intent, not the fifth iteration of proxy-header semantics.
The death spiral is not a reason to avoid automation. It is a reason to treat severity gates, shared memory, and consistency guards as first-class engineering — as important as your test suite or deploy pipeline.
Mergestorm runs Vortex and Cyclone on every push with these guardrails baked in. Start with 100 free reviews per month and watch how fast a PR moves when the bots stop fighting each other.